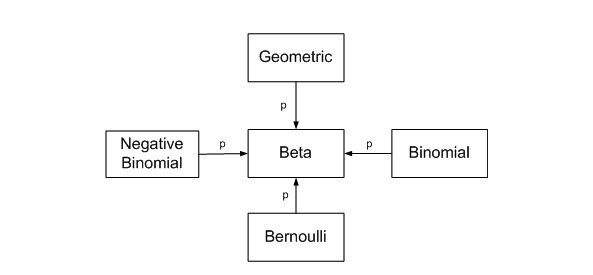
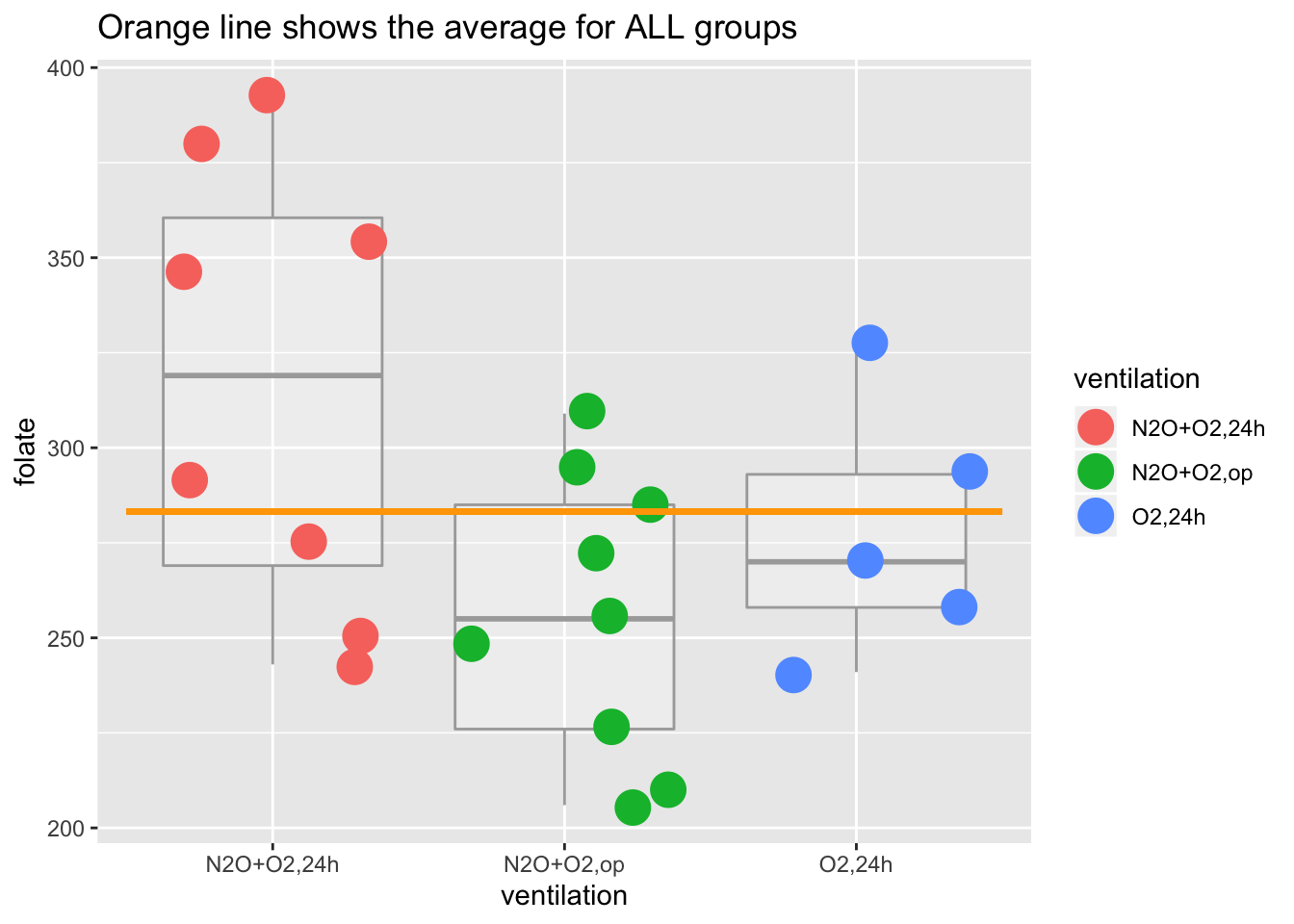
The maximum likelihood estimation (MLE) is a general method to find the function that most likely fits the available data; it therefore addresses a central problem in data sciences. Depending on the model, the math behind MLE can be very complicated, but an intuitive way to think about it is through the following thought experiment….
MLE – The Maximum Likelihood Estimate
Posted on