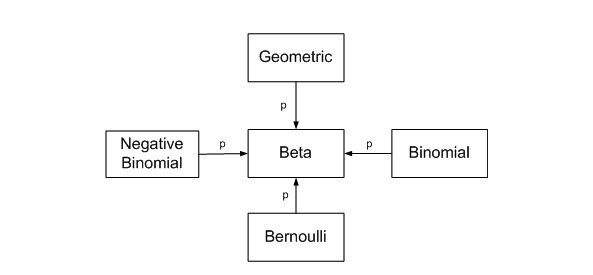
The hypergeometric distribution is used to solve the classic “balls in an urn” proble. Suppose one has 7 red balls and 3 white ball in an urn, and draws 2 balls. What is the probability that both balls are white? Let’s make a function to allow quick replication Other combinations
The hypergeometric distribution
Posted on