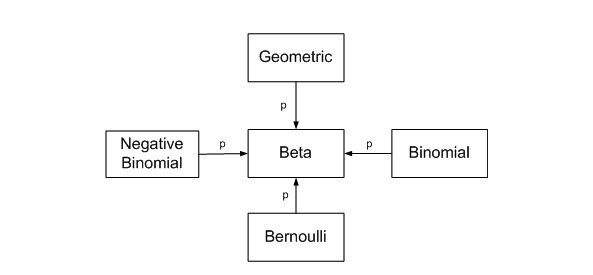
Definition Using the mean Using ranges for the prior Informative vs. uninformative priors Mean, median, variance Highest Density Interval References Addenda Definition The Beta distribution represents a probability distribution of probabilities. It is the conjugate prior of the binomial distribution (if the prior and the posterior distribution are in the same family, the prior and posterior…
The beta distribution
Posted on